Recently I spent time with a customer who, in their words, have gone “all in” on Microsoft. From corporate IT to developer tools to application platforms. Not so long ago, that kind of statement would have made me shudder with despair, so it’s testament to how Microsoft have reinvented themselves that using their tools has been such a pleasant experience.
For me, working mostly with the Azure DevOps (ADO) suite of applications, the standout tool was ADO Pipelines.
The thing that really appealed to me was the interface. While the azure-pipelines.yml that defines tasks is nice and clear, there is also a nice, easy-to-use sidebar which lets you fill in a form and have it generate and fill in the appropriate YAML for you, very similar to the pipeline syntax reference in Jenkins.
Creating a Quarkus Native Image with ADO Pipelines
ADO Pipelines have a huge amount of extensions but none for GraalVM yet, so it might first appear that you would be stuck with JVM-based container images. Not so; the lovely folks over at Quarkus have provided a helpful bunch of container images on Quay.io which can be used in a multi-stage build.
Create a Multistage Dockerfile
Below is my Dockerfile which will build any Maven Quarkus project with GraalVM 19.2.1:
FROM quay.io/quarkus/centos-quarkus-maven:19.2.1 AS build
COPY ./pom.xml ./pom.xml
COPY ./src ./src
RUN mvn -Pnative package -DskipTests
FROM registry.access.redhat.com/ubi8/ubi-minimal
WORKDIR /work/
COPY --from=build /project/target/*-runner /work/application
RUN chmod 775 /work
EXPOSE 8080
CMD ["./application", "-Dquarkus.http.host=0.0.0.0"]
After creating a new Quarkus project (or, like me, stealing borrowing one from the Quarkus quickstarts repository), the above can be added as a new Dockerfile next to the (probably already present) src/main/docker/Dockerfile.jvm and src/main/docker/Dockerfile.native files.
Before carrying on, it’s worth testing to make sure everything builds correctly:
podman build -f src/main/docker/Dockerfile.multistage -t quarkus-quickstart/rest-client .
podman run -it quarkus-quickstart/rest-client
Create a connection to Docker Hub
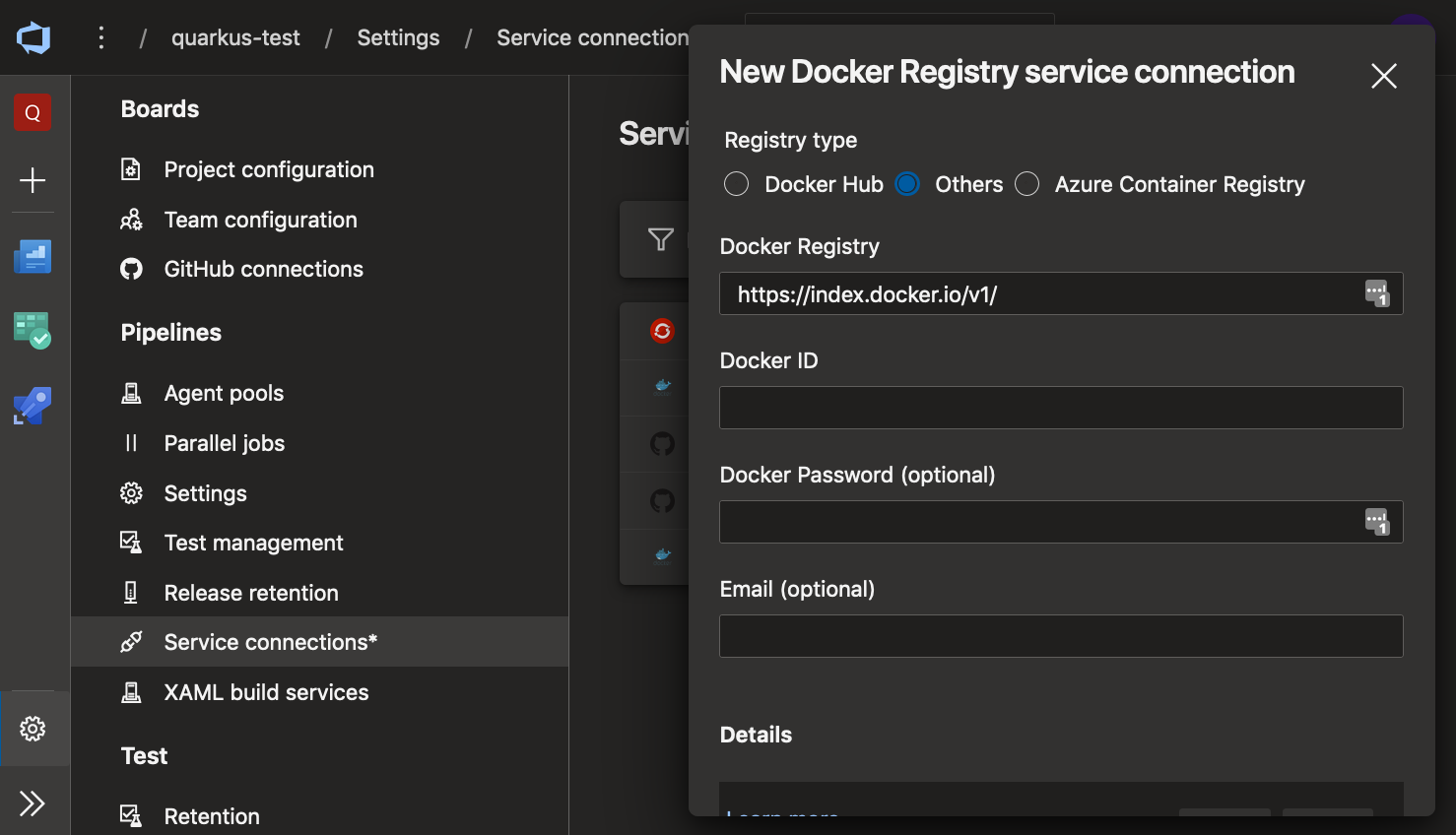
To get all this running in Azure, we first need to create a Service Connection to Docker Hub so that we can push our images without exposing credentials in the azure-pipelines.yml file. I’m using Docker Hub because, although we could easily use any other registry, like the internal OpenShift registry, it’s a bit involved for this blog post.
In the Azure DevOps dashboard, click the cog icon at the bottom left and scroll down the Project Settings to “Service connections”. Create a new connection of type “Docker Registry” like in the screenshot:
Add a docker buildAndPush task
Next, we can switch to the pipeline view and add a Docker task by choosing the connection we just created in the dropdown, and filling in the form fields appropriately:
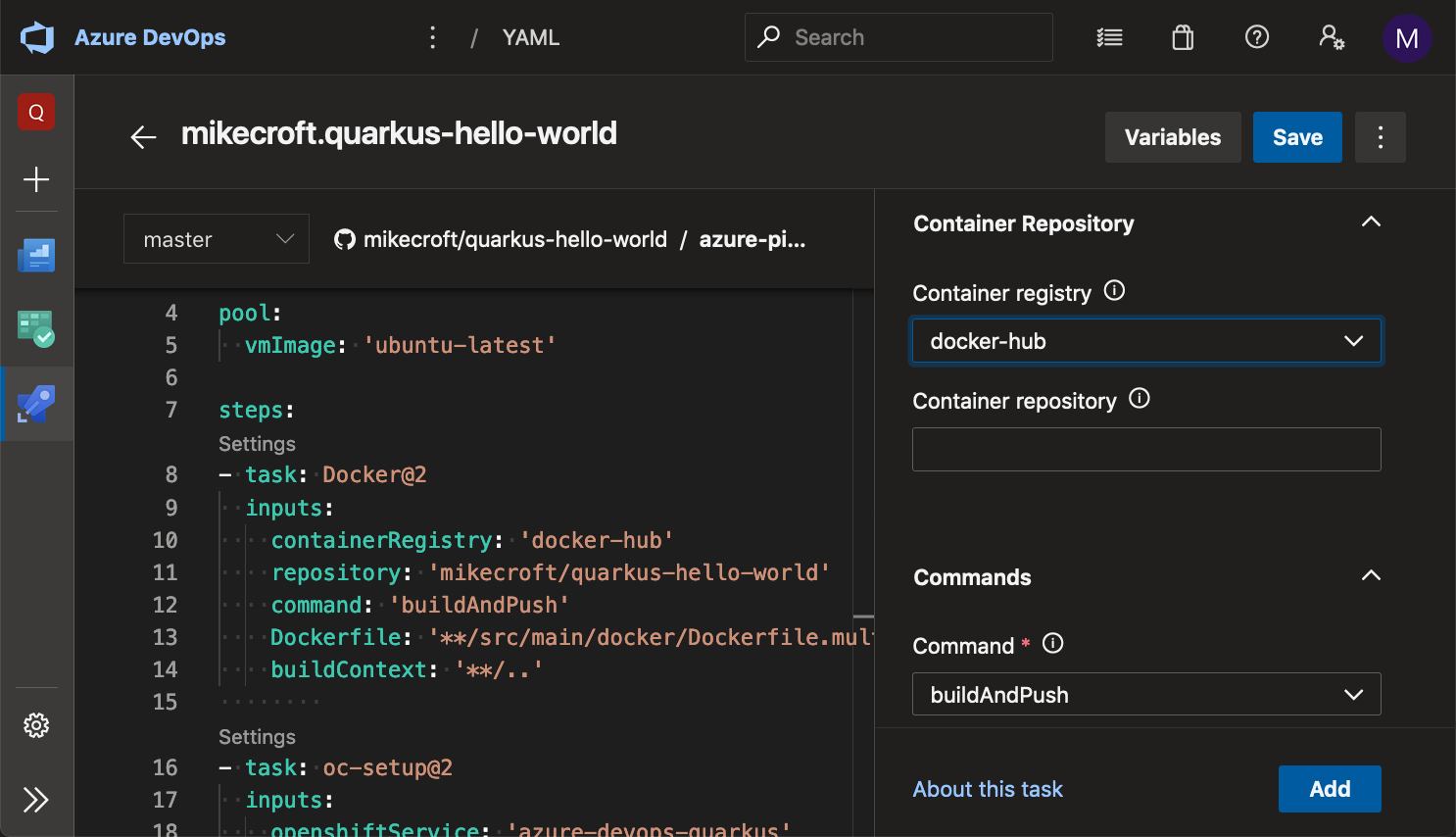
Clicking the “Add” button will insert the correct YAML wherever the cursor is in the left-hand editing pane.
Deploy the image to OpenShift
Now we’ve got Azure building our image, we haven’t actually achieved much more than moving processing off our own machine. The logical next-step would be to deploy the image to a cluster where it could be used for integration testing and, hopefully, on to production.
Fortunately, our lives can further be made easier thanks to the OpenShift extension for ADO Pipelines. After adding this extension, we can add a new service connection exactly the same as we did for Docker Hub.
To use the extension, we first need a task to set up the oc binary:
- task: oc-setup@2
inputs:
openshiftService: 'azure-devops-quarkus'
Then we can add an OpenShift task to run an oc command:
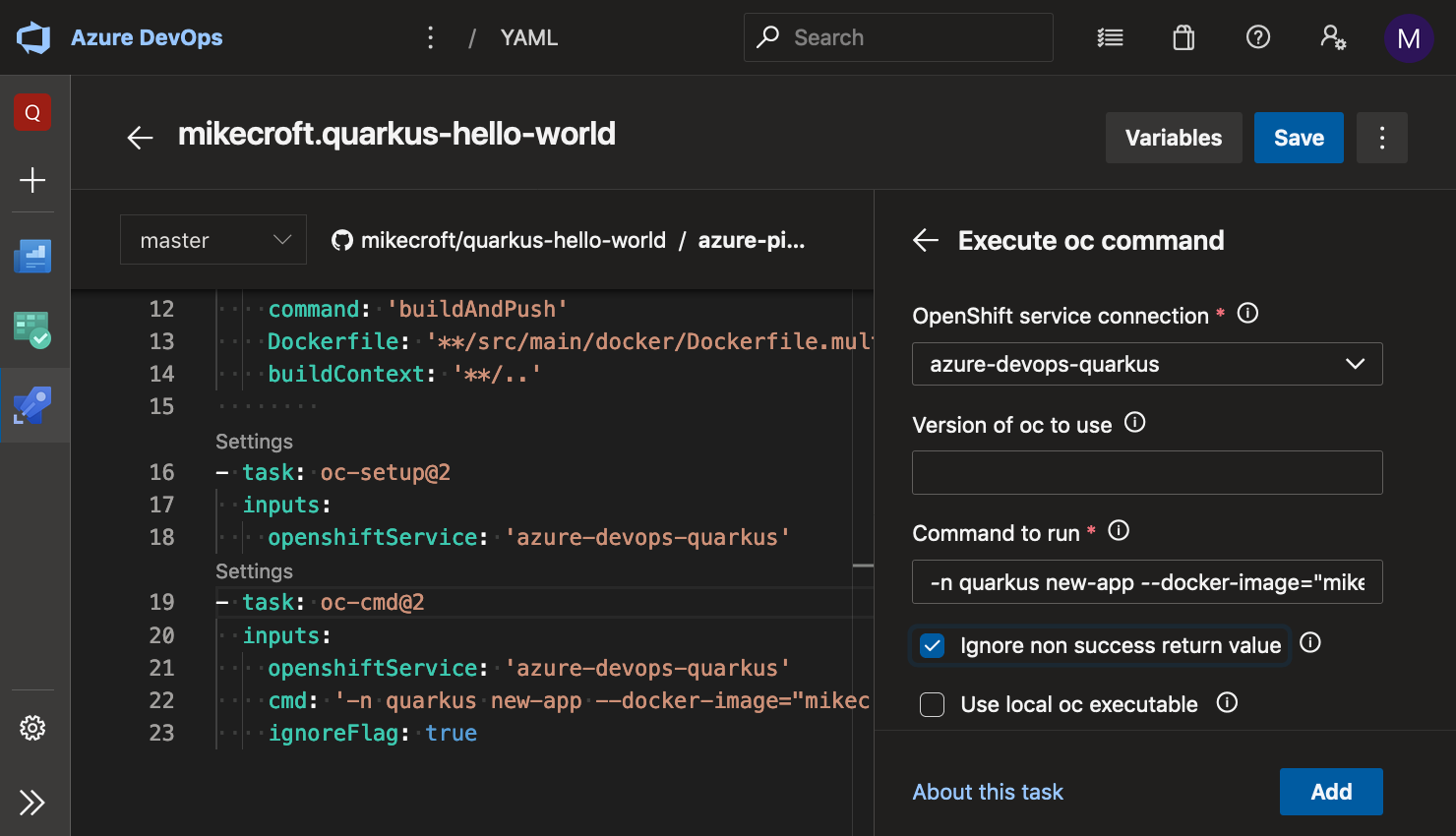
Note that I’m only using oc new-app here to deploy the app, along with the built-in pipeline environment variable $(Build.BuildId) to create a new OpenShift Deployment config with the same image that I just built. This isn’t ideal because you would need to remove and recreate the app with each pipeline run. ADO Pipelines does give some quite advanced conditional statements, so it would be relatively straightforward to check that the project and DeploymentConfig already exist, and then running an oc patch instead, or even simply creating an imagestream to be even more hands-off.
Once complete, the full pipeline looks like this:
trigger:
- master
pool:
vmImage: 'ubuntu-latest'
steps:
- task: Docker@2
inputs:
containerRegistry: 'docker-hub'
repository: 'mikecroft/quarkus-hello-world'
command: 'buildAndPush'
Dockerfile: '**/src/main/docker/Dockerfile.multistage'
buildContext: '**/..'
- task: oc-setup@2
inputs:
openshiftService: 'azure-devops-quarkus'
- task: oc-cmd@2
inputs:
openshiftService: 'azure-devops-quarkus'
cmd: '-n quarkus new-app --docker-image="mikecroft/quarkus-hello-world:$(Build.BuildId)"'
ignoreFlag: true
The Future of Pipelines in OpenShift
My preference is usually for builds to happen inside OpenShift rather than with external tools. The experience of using third party tooling can vary a lot, so it’s impressive that ADO Pipelines felt so natural to use.
Since it looks like Tekton is the future for builds in OpenShift, I really hope the “getting started” experience will be as nice as it was for me with ADO Pipelines. There’s already a dashboard project for Tekton which is maturing well, so there’s lots of reasons to have high expectations.
I hope to have time to create a similar pipeline to this one with Tekton, soon although I expect that a comparison at this stage while there is still so much work going on in the various Tekton projects may not be fair!
